1️⃣ 테스트용 파일 준비 (examples\sample.csv)
name,age,score
Alice,30,85
Bob,25,90
2️⃣ main.py 작성 및 연동
# app/main.py
import typer
from app.pipeline.reader import read_input
from app.utils.logger import get_logger
app = typer.Typer()
logger = get_logger(__name__)
@app.command()
def run(
input_path: str = typer.Option(..., help="입력 파일 또는 폴더 경로"),
output_path: str = typer.Option("./output", help="출력 경로"),
):
logger.info("자동화 파이프라인 시작")
dataframes = read_input(input_path)
logger.info(f"총 DataFrame 개수: {len(dataframes)}")
logger.info("작업 완료")
if __name__ == "__main__":
app()
실행결과

3️⃣ processor.py
-. 이 파일은 입력(DataFrame)을 받아서, 규칙 기반으로 가공된 DataFrame을 반환한다.
-. 파일 입출력은 하지 않고, 순수 함수에 가깝게 작성하는 것이 원칙.
# app/pipeline/processor.py
from typing import List
import pandas as pd
from app.utils.logger import get_logger
logger = get_logger(__name__)
def process_dataframes(dfs: List[pd.DataFrame]) -> List[pd.DataFrame]:
"""
여러 DataFrame을 받아 규칙 기반으로 가공한다.
"""
processed: List[pd.DataFrame] = []
for idx, df in enumerate(dfs):
logger.info(f"DataFrame 처리 시작: index={idx}")
try:
processed_df = _process_single_dataframe(df)
processed.append(processed_df)
except Exception:
logger.exception(f"DataFrame 처리 실패: index={idx}")
logger.info(f"총 처리 완료 DataFrame 수: {len(processed)}")
return processed
def _process_single_dataframe(df: pd.DataFrame) -> pd.DataFrame:
"""
DataFrame 하나에 대한 가공 로직
"""
df = df.copy()
df = _normalize_columns(df)
df = _apply_rules(df)
return df
def _normalize_columns(df: pd.DataFrame) -> pd.DataFrame:
"""
컬럼명 정규화
"""
df.columns = (
df.columns
.str.strip()
.str.lower()
.str.replace(" ", "_")
)
logger.debug(f"정규화된 컬럼: {list(df.columns)}")
return df
def _apply_rules(df: pd.DataFrame) -> pd.DataFrame:
"""
예시 규칙:
- score >= 90 : grade = 'A'
- score >= 80 : grade = 'B'
- 그 외 : 'C'
"""
if "score" not in df.columns:
logger.warning("score 컬럼이 없어 규칙 적용 스킵")
return df
def classify(score):
if score >= 90:
return "A"
if score >= 80:
return "B"
return "C"
df["grade"] = df["score"].apply(classify)
logger.info("grade 컬럼 생성 완료")
return df
scroe에 대한 grade 기준을 나누는 것으로 간단한 예시를 구현.
DataFrame -> DataFrame으로 가공한다는 큰 틀을 벗어나지 않는다면, 입력 데이터에 따른 구현방식은 수정 가능.
4️⃣ main 함수에 processor 연결
# app/main.py
import typer
from app.pipeline.reader import read_input
from app.utils.logger import get_logger
from app.pipeline.processor import process_dataframes
app = typer.Typer()
logger = get_logger(__name__)
@app.command()
def run(
input_path: str = typer.Option(..., help="입력 파일 또는 폴더 경로"),
output_path: str = typer.Option("./output", help="출력 경로"),
):
logger.info("자동화 파이프라인 시작")
dfs = read_input(input_path)
processed_dfs = process_dataframes(dfs)
logger.info(f"가공 완료 DataFrame 수: {len(processed_dfs)}")
logger.info("작업 완료")
if __name__ == "__main__":
app()
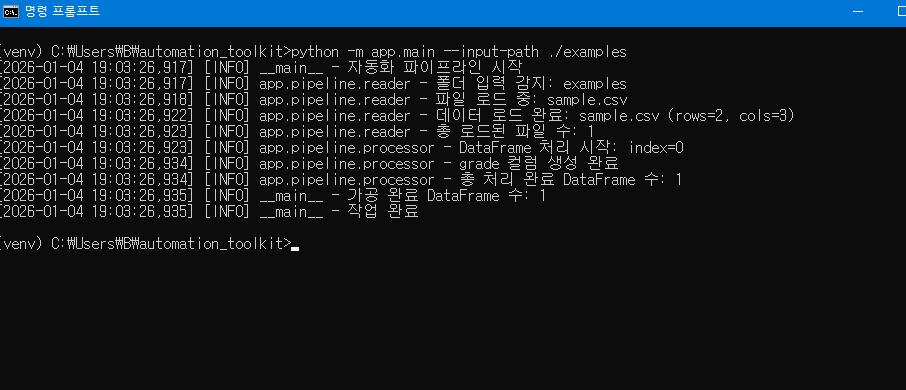
실행결과
'업무 자동화 툴 킷(Automation toolkit, A.T)' 카테고리의 다른 글
| 업무 자동화 툴 킷(Automation toolkit, A.T) - 3일차 (0) | 2026.01.06 |
|---|---|
| 업무 자동화 툴 킷(Automation toolkit, A.T) - 1일차 (0) | 2026.01.02 |
| 파이썬 실습 프로젝트 : 업무 자동화 툴 킷(Automation toolkit, A.T) (0) | 2026.01.02 |